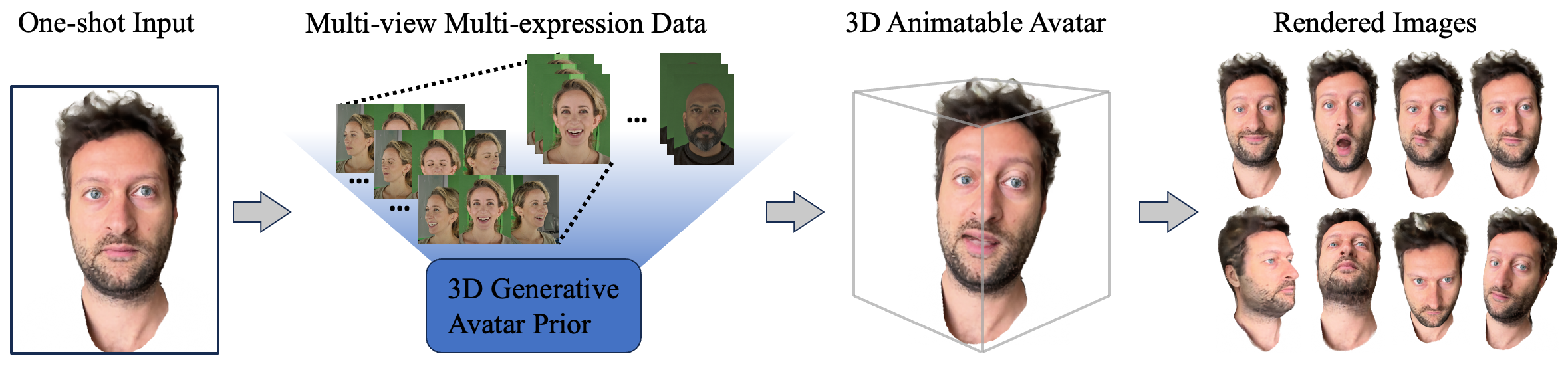
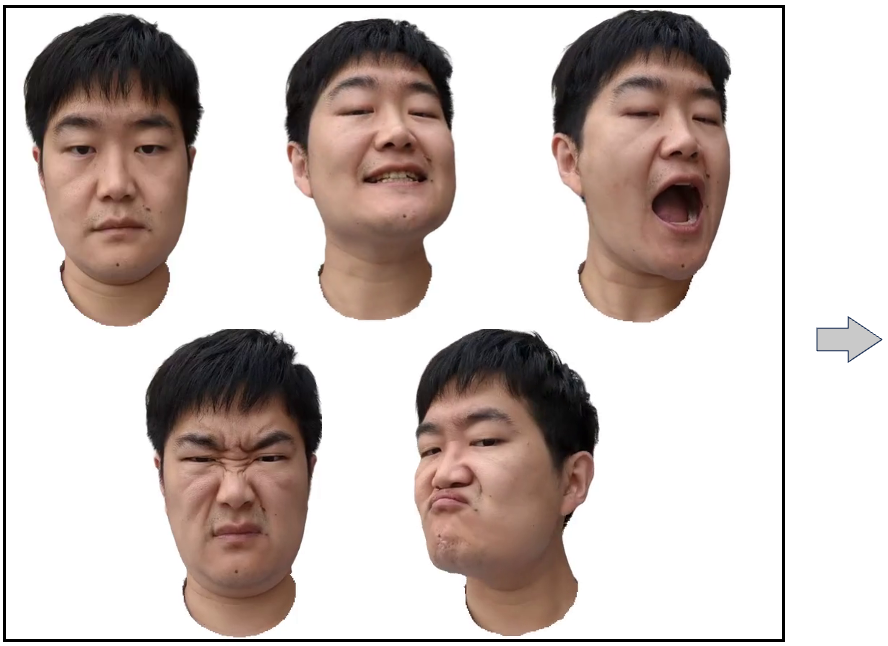
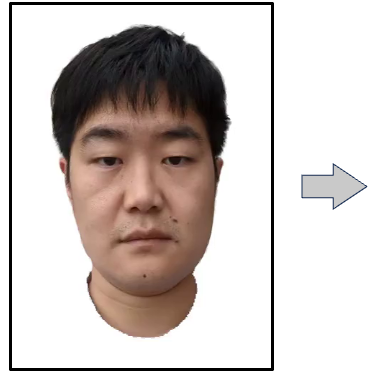
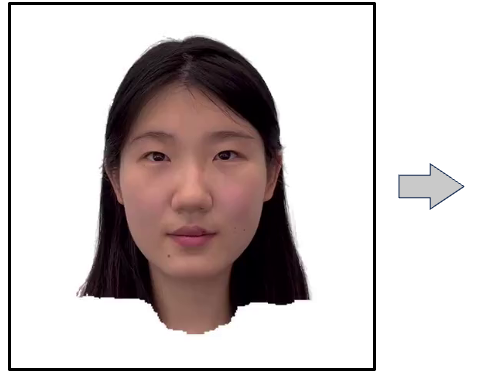
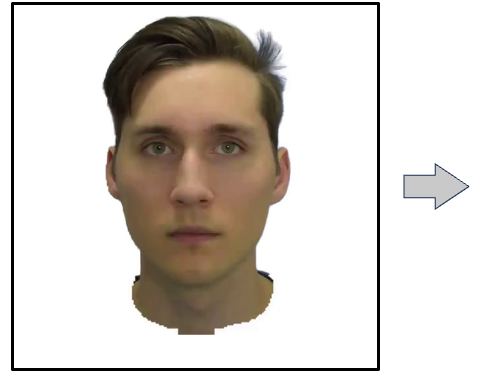
We present a new approach to generate an animatable photo-realistic avatar from only a few or even one image of the target
person. We encode the geometry and appearance by leveraging a neural radiance field that is generated by a 3D generative model learned
from multi-view multi-expression data. With this model, we render the high fidelity head avatar seen from a novel view.
One-shot Avatar Creation
Training data
Input Driving Video Rendered Avatar Rendered Depth
Five-shot Avatar Creation
Training data
Input Driving Video Rendered Avatar Rendered Depth
Abstract
Traditional methods for constructing high-quality, personalized head avatars from monocular videos demand extensive
face captures and training time, posing a significant challenge for scalability. This paper introduces a novel approach
to create high quality head avatar utilizing only a single or a few images per user. We learn a generative model for
3D animatable photo-realistic head avatar from a multi-view dataset of expressions from 2407 subjects, and leverage
it as a prior for creating personalized avatar from few-shot images. Different from previous 3D-aware face generative
models, our prior is built with a 3DMManchored neural radiance field backbone, which we show to be more effective for
avatar creation through auto-decoding based on few-shot inputs. We also handle unstable 3DMM fitting by jointly optimizing
the 3DMM fitting and camera calibration that leads to better few-shot adaptation. Our method demonstrates compelling
results and outperforms existing state-of-the-art methods for few-shot avatar adaptation, paving the way for more efficient
and personalized avatar creation.
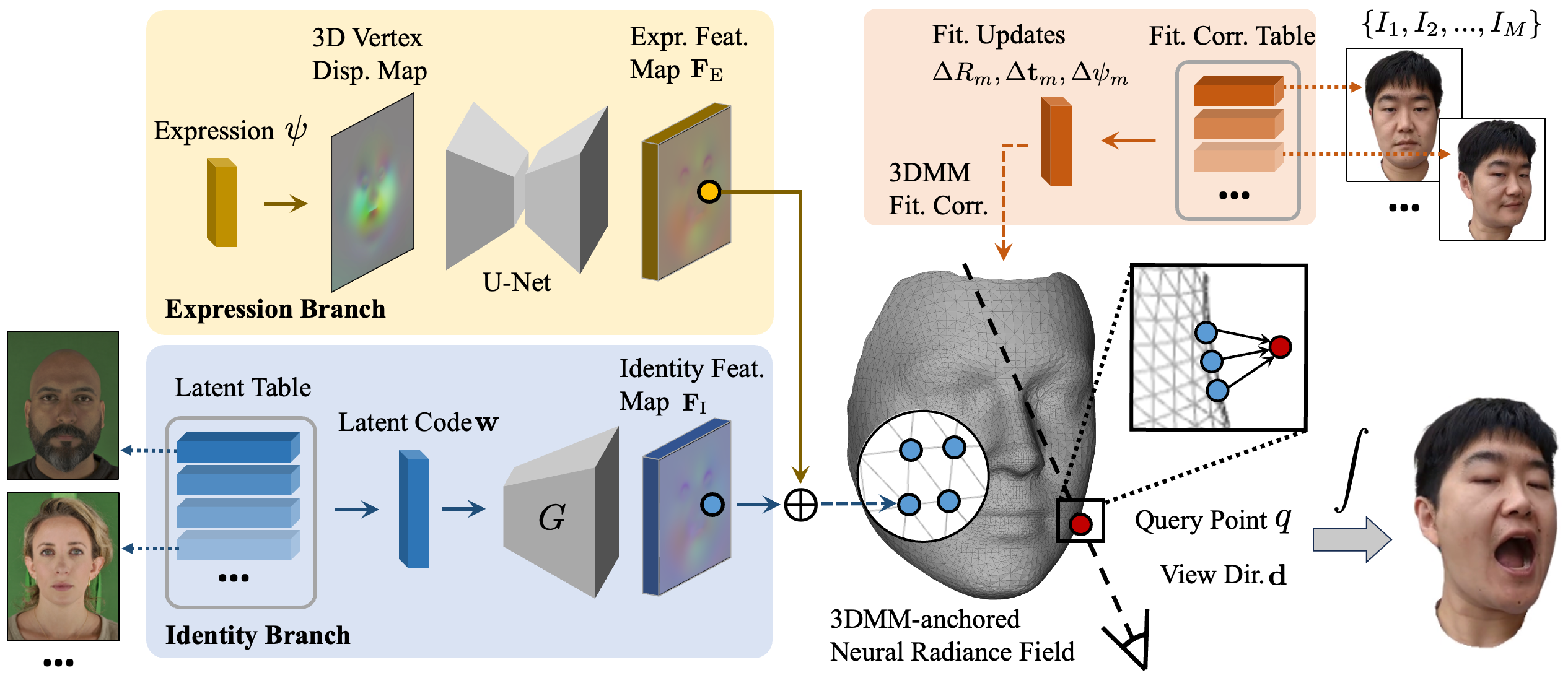
Overview
We adopt a 3DMM-anchored neural radiance field (NeRF) as our avatar representation, where the feature for each query point is
aggregated from its k-Nearest-Neighbors in the 3DMM vertices and decoded to color and density via a shallow MLP network.
The StyleGAN2 generator based identity branch encodes personalized characteristics into an identity feature map from a latent
code uniquely assigned to a training subject. The expression branch produces an expression feature map from 3DMM expression code
via a U-Net. The summation of two feature maps are then sampled by 3DMM vertices via texture coordinates to establish the
3DMM-anchored neural radiance field. For few-shot adaptation, we initialize the target latent code with the mean latent code
across training subjects and jointly optimize it with the model weights as well as per-frame 3DMM fitting corrections on given
images of the target person.
Results of Five-shot Avatar Creation
Training data
Input Driving Video Rendered Avatar Rendered Depth
Training data
Input Driving Video Rendered Avatar Rendered Depth
Training data
Input Driving Video Rendered Avatar Rendered Depth
Training data
Input Driving Video Rendered Avatar Rendered Depth
Training data
Input Driving Video Rendered Avatar Rendered Depth
Results of One-shot Avatar Creation
Training data
Input Driving Video Rendered Avatar Rendered Depth
Training data
Input Driving Video Rendered Avatar Rendered Depth
Training data
Input Driving Video Rendered Avatar Rendered Depth
Training data
Input Driving Video Rendered Avatar Rendered Depth
Training data
Input Driving Video Rendered Avatar Rendered Depth
Qualitative Comparison
Labels - From left to right: (1) Next3D [1], (2) MonoAvatar [2],
(3) Ours, (4) Ground Truth (Input Driving Video)
(Since Next3D is trained with cropped facial images, we apply the same cropping for all methods here for a fair comparison.
Note that the "jitters" in the videos below is caused by inconsistent cropping bounding boxes generated during data
processing of Next3D, which are compared based on five estimated facial landmarks.)
Comparison on Five-shot avatar creation:
Next3D MonoAvatar Ours Ground Truth
Next3D MonoAvatar Ours Ground Truth
Next3D MonoAvatar Ours Ground Truth
Next3D MonoAvatar Ours Ground Truth
Next3D MonoAvatar Ours Ground Truth
Next3D MonoAvatar Ours Ground Truth
Comparison on One-shot avatar creation:
Next3D MonoAvatar Ours Ground Truth
Next3D MonoAvatar Ours Ground Truth
Next3D MonoAvatar Ours Ground Truth
Next3D MonoAvatar Ours Ground Truth
Next3D MonoAvatar Ours Ground Truth
Next3D MonoAvatar Ours Ground Truth
Avatar Generation
Avatar generation in novel identity by interpolating latent code of two subjects.
Driving Video Generated Avatar Rendered Depth
References
[1] Jingxiang Sun, Xuan Wang, Lizhen Wang, Xiaoyu Li, Yong Zhang, Hongwen Zhang, and Yebin Liu. "Next3d: Generative neural texture rasterization for 3d-aware head avatars." In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023.
[2] Ziqian Bai, Feitong Tan, Zeng Huang, Kripasindhu Sarkar, Danhang Tang, Di Qiu, Abhimitra Meka et al. "Learning Personalized High Quality Volumetric Head Avatars from Monocular RGB Videos." In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023.